A Strategic Framework for Prompt Engineering and Beyond
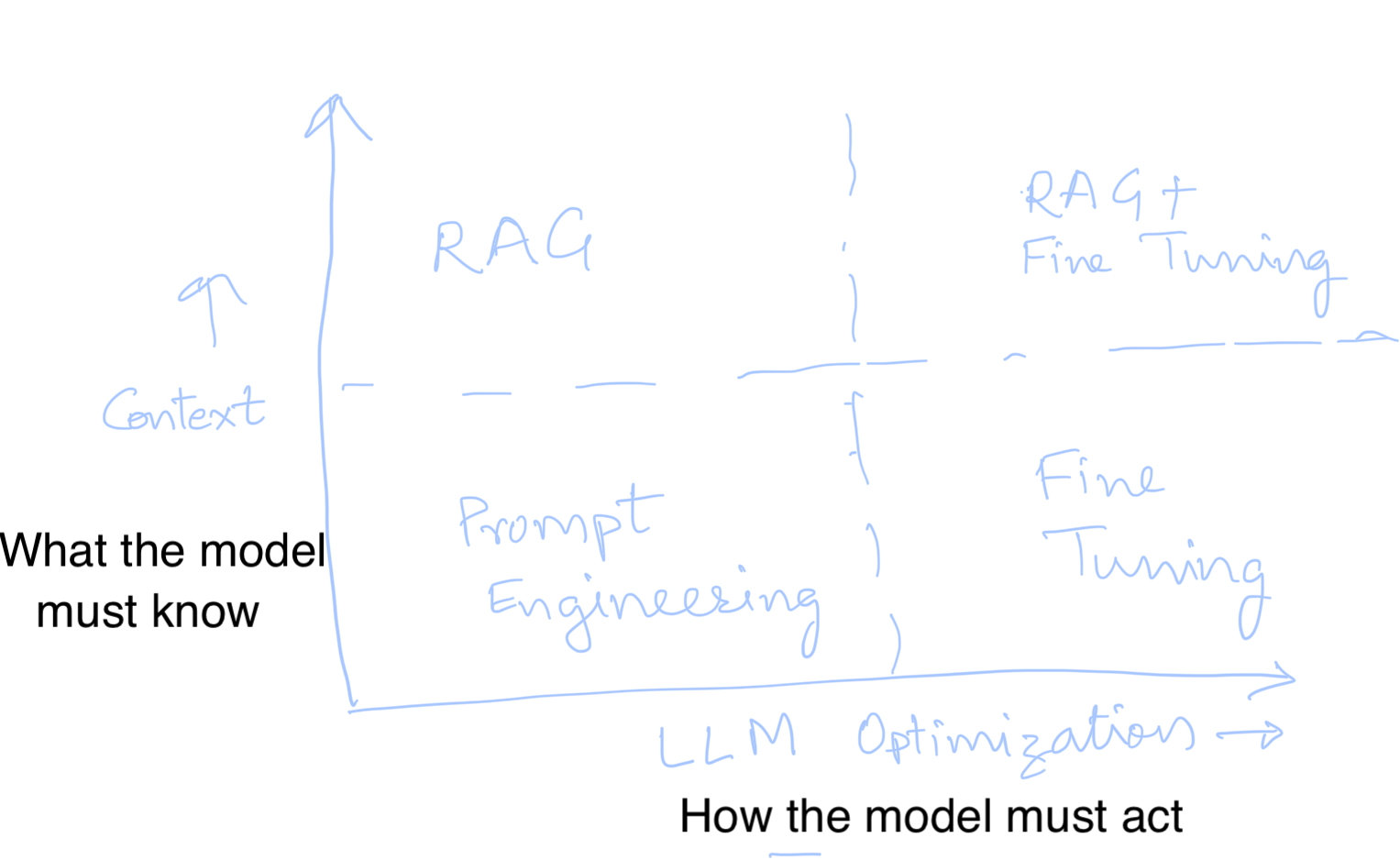
A strategic framework on choosing amongst prompt engineering, RAG, and Fine Tuning.
As we continue to push the boundaries of what AI can achieve, it’s crucial to use a strategic framework to guide implementation efforts when integrating large language models (LLMs). As the diagram shows, it is important to think along two dimensions: (i) how the model must act, (ii) what the model needs to know. Here’s a basic high-level approach to consider:
Choosing the Right Tools: Prompt Engineering, RAG, and Fine-Tuning
-
Prompt Engineering: Start here for its simplicity and cost-effectiveness. It’s often sufficient for many applications, relying solely on crafting the right prompts to guide the model’s responses. This method is excellent for maintaining low latency and costs while achieving decent accuracy. Combine this with agentic flow if necessary.
-
Retrieval-Augmented Generation (RAG): Opt for RAG when the context necessary for generating accurate responses cannot be fully embedded within a prompt or when doing so would cause unacceptable costs or delays. RAG integrates external knowledge dynamically, enhancing the model’s ability to provide contextually rich answers.
-
Fine-Tuning: This is your go-to when specific instructions for how the model should behave cannot be efficiently encoded within a prompt. Fine-tuning adjusts the model’s parameters to align closely with your unique requirements, offering tailored responses that are directly in line with expected outcomes.
Iterative Approach for Optimization
-
Agentic Flow: Begin with prompt engineering combined with an agentic flow to gauge performance against your benchmarks of accuracy, latency, and cost.
-
Iterative Refinement: If initial strategies don’t meet the desired thresholds, iteratively apply RAG and fine-tuning. This process ensures that each iteration brings you closer to meeting both performance and cost objectives. Even within RAG and fine-tuning, one can go deeper and optimize each step further.
Final Thoughts
Implementing LLMs isn’t a one-size-fits-all approach. It requires a balanced consideration of performance metrics, cost, and the specific demands of your application. By strategically choosing between prompt engineering, RAG, and fine-tuning, you can optimize your implementations to not only meet but exceed your operational goals.